VED – GIẢI PHÁP KHO DỮ LIỆU TRÊN NỀN TẢNG ĐIỆN TOÁN ĐÁM MÂY
Trong kỷ nguyên cách mạng công nghiệp 4.0 cùng với sự phát triển rất nhanh của công nghệ, nhu cầu lưu trữ và phân tích dữ liệu đã trở thành một yếu tố quyết định trong sự phát triển của các doanh nghiệp. Việc xây dựng một kho dữ liệu để lưu trữ dữ liệu tập trung và phân tích để đưa ra các quyết định kinh doanh đã thở thành một xu thế trong thời gian gần đây. Nắm rõ được nhu cầu của thị trường cũng như các yêu cầu đặc thù về việc lưu trữ dữ liệu cho từng nhóm tổ chức/doanh nghiệp, VDI đã nghiên cứu, xây dựng và phát triển giải pháp kho dữ liệu VED – VDI Elastic Data Lake (Kho dữ liệu trên nền tảng điện toán đám mây). Vậy VED là gì? Cùng VDI tìm hiểu bài viết dưới đây nhé:

1. VED là gì?
VDI Elastic Datalake (VED) là giải pháp datalake (hồ dữ liệu) được phát triển theo mô hình cloud-native, hỗ trợ lưu trữ, phân tích và xử lý các loại dữ liệu đa dạng, từ nhiều nguồn khác nhau. Giải pháp hỗ trợ doanh nghiệp, tổ chức lấy dữ liệu làm trung tâm, khai thác hiệu quả dữ liệu và nhanh chóng đưa ra các quyết định kinh doanh. Ngoài ra, với mô hình cloud-native, giải pháp có thể dễ dàng được triển khai trên tất cả các nhà cung cấp hạ tầng cloud hiện nay, đem lại tính linh hoạt và khả năng tối ưu chi phí cho doanh nghiệp.
2. Các công nghệ sử dụng trong VED
– Công nghệ quản lý container: Giải pháp được triển khai trên hạ tầng quản lý container, sử dụng giải pháp Kubernetes (giải pháp quản lý điều phối container) để tự động hóa việc triển khai, mở rộng hệ thống và quản lý nâng cấp phần mềm.
– Công nghệ xử lý dữ liệu lớn: Giải pháp sử dụng các công cụ của bộ giải pháp Hadoop để quản lý dữ liệu, lập lịch phân tích, lưu trữ và xử lý dữ liệu.
– Công nghệ truyền tài (streaming) dữ liệu: Giải pháp sử dụng công cụ Apache Kafka để xây dựng các luồng truyền tải cho từng loại dữ liệu.
– Công tích hợp và xử lý dữ liệu (ETL – Extract, Transform, Load): Giải pháp sử dụng công nghệ mã nguồn mở Apache Spark, Apache Airflow để xây dựng các luồng ETL tích hợp và xử lý dữ liệu.
– Công nghệ cơ sở dữ liệu: Giải pháp sử dụng các cơ sở dữ liệu mã nguồn mở (MySQL, PostgreSQL) để lưu trữ các dữ liệu có cấu trúc đã được tinh chỉnh.
– Công nghệ phân tích, mô hình hóa dữ liệu: Giải pháp sử dụng công nghệ Power BI và công nghệ mã nguồn mở Tableau để xây dựng các báo cáo, dashboard, visualization cho việc phân tích, mô hình hóa, trực quan hóa dữ liệu.
– Công nghệ nhận thực quản lý truy cập: Giải pháp sử dụng công nghệ Kerberos để thực hiện xác thực và cấp quyền truy cập cho người dùng để nâng cao tính bảo mật.
3. Tính năng bảo mật của VED
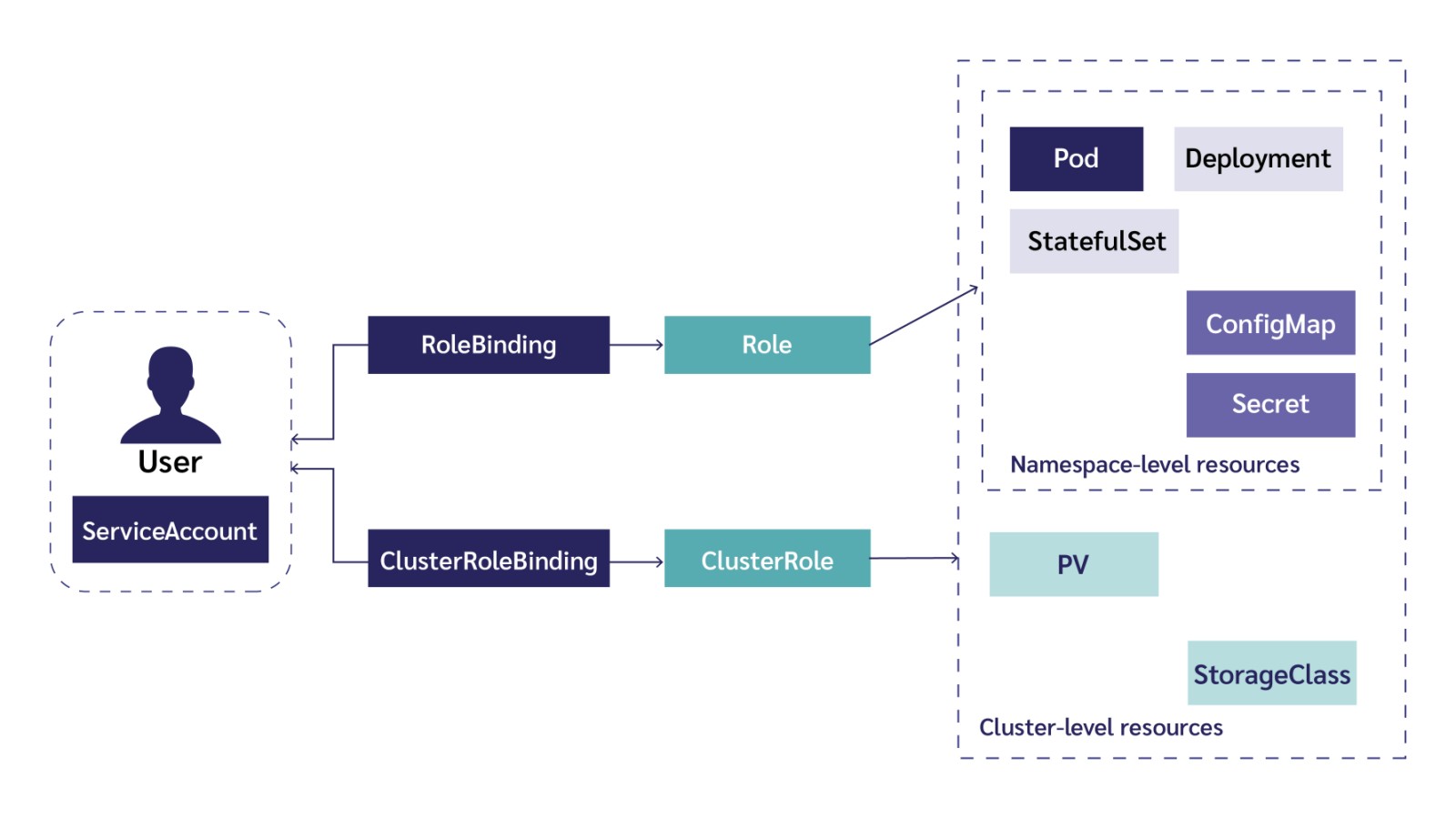
– Nền tảng Kubernetes cung cấp tính năng Role-Based Access Control (RBAC), hỗ trợ quản trị viên tạo các tài khoản và gán quyền phù hợp cho từng tài khoản. Khi cấu hình RBAC cho module Apache Spark, chỉ có các pod sử dụng các account được định danh trước mới có thể thực hiện các tiến trình phân tích dữ liệu trên hệ thống Kubernetes.
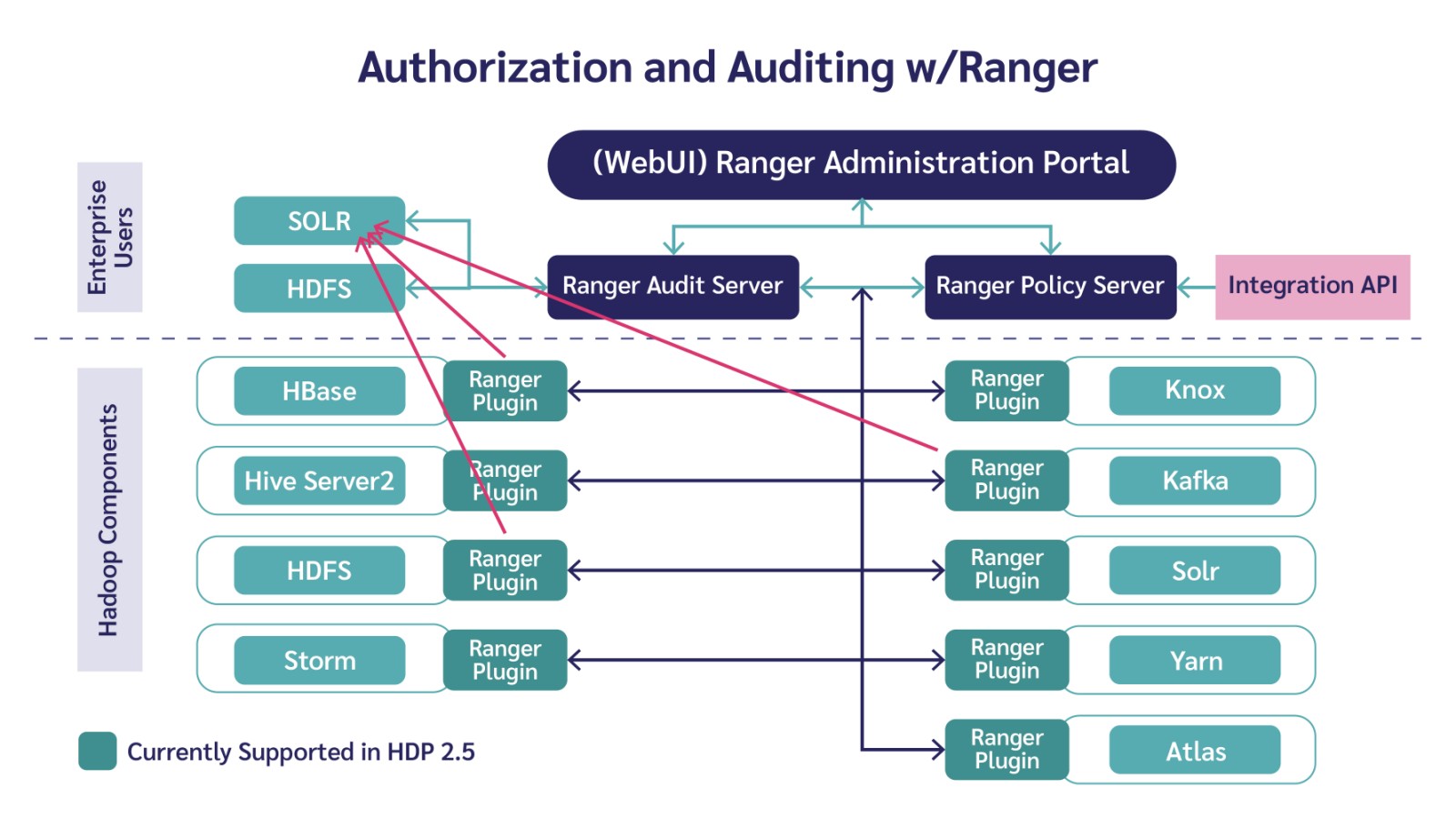
– Công cụ Apache Ranger thuộc bộ giải pháp Hadoop cho phép định nghĩa và cấp các quyền (policy) cho phép người dùng truy cập vào các dữ liệu nhất định trong kho dữ liệu. Apache Ranger cũng cung cấp audit log để kiểm tra các tác động trong hệ thống Hadoop.
– Công cụ Kerberos để xác thực và nhận thực cho người dùng, đảm bảo ngăn chặn sự truy cập bất hợp pháp của hacker dẫn đến thất thoát dữ liệu trong kho hoặc hồ dữ liệu.
– Giải pháp được triển khai trong hạ tầng cơ sở dữ liệu của khách hàng nên hoàn toàn được bảo vệ bởi các hệ thống tường lửa bảo mật cho cơ sở dữ liệu.
4. Ưu điểm nổi trội của VED
Giải pháp được triển khai trên nền tảng quản lý container (Kubernetes) mang lại khả năng tương thích với tất cả các nhà cung cấp dịch vụ điện toán đám mây công cộng (public cloud) hiện nay như Amazon Web Services, Microsoft Azure, Google Cloud Platform. Giải pháp cũng có thể được triển khai ngay tại trung tâm dữ liệu của khách hàng. Do đó, giải pháp mang lại sự linh hoạt và đơn giản khi triển khai và cài đặt. Khách hàng có thể linh động sử dụng bất kỳ hạ tầng cloud nào để triển khai giải pháp. Ngoài ra, trong quá trình sử dụng, khách hàng có thể dễ dàng dịch chuyển (migrate) giải pháp giữa các hạ tầng cơ sở dữ liệu.
Ngoài ra, nền tảng quản lý container cũng đem lại khả năng mở rộng linh hoạt cho dung lượng của hệ thống nhờ vào các tính năng của công nghệ Kubernetes:
– Tự động phục hồi: Kubernetes hỗ trợ khởi động lại các container chạy dịch vụ bị lỗi, thay thế và xoá các container không phản hồi lại cấu hình health check
– Điều hành, phân bố container trên nhiều máy chủ
– Kiểm soát, tự động triển khai và cập nhật ứng dụng
– Quản lý các dịch vụ, đảm bảo các ứng dụng được triển khai đúng cách
– Mở rộng dung lượng ứng dụng chưa trong các container
– Tận dụng phần cứng nhiều hơn để tối ưu hoá tài nguyên cần thiết cho việc chạy ứng dụng trên cơ sở hạ tầng của khách hàng
Giải pháp tận dụng bộ công cụ Hadoop giúp mang lại các ưu điểm sau khi xử lý dữ liệu:
– Hỗ trợ lưu trữ, tích hợp đa dạng các loại dữ liệu: dữ liệu có cấu trúc, bán cấu trúc, phi cấu trúc
– Xử lý dữ liệu lớn là dữ liệu luôn sẵn sàng cho việc phân tích
– Dữ liệu thô có được sử dụng để phân tích, sử dụng luôn mà không cần thông qua xử lý và làm sạch
– Có khả năng tích hợp với các giải pháp thông tin như máy học, trí tuệ nhân tạo để đưa ra các quyết định chính xác
5. Lợi ích giải pháp mang lại cho Tổ chức/Doanh nghiệp
– Quản lý tập trung: Chuyển đổi số doanh nghiệp dẫn đến tình trạng doanh nghiệp cần xử lý lượng dữ liệu khổng lồ từ nội bộ và bên ngoài. Do đó, giải pháp Hồ dữ liệu (Data Lake) hay Kho dữ liệu tổng hợp (Data Warehouse) trở thành công cụ quản lý tất cả các thông tin một cách tập trung, khoa học. Data Lake – Data Warehouse giúp mọi người tiết kiệm thời gian tìm kiếm, phân loại và tối ưu dữ liệu.
– Nâng cao chất lượng và tính thống nhất dữ liệu: Data Warehouse cho phép doanh nghiệp loại bỏ các dữ liệu thừa và chuẩn hóa hoạt động thu thập thông tin. Doanh nghiệp sẽ hệ thống dữ liệu nguồn đáp ứng đúng yêu cầu hoạt động, thống nhất đồng bộ trong toàn bộ máy. Điều này giúp nhân viên dễ dàng truy cập dữ liệu chính xác mọi lúc mọi nơi, giảm tỷ lệ sai sót và nhầm lẫn thông tin. Ngoài ra, tính thống nhất cũng khiến quá trình đào tạo hội nhập cho nhân viên mới của doanh nghiệp diễn ra thuận lợi hơn.
– Tạo ra lợi thế cạnh tranh: Các nhà quản lý, lãnh đạo có thể phân tích, tìm hiểu sâu sắc những vấn đề của doanh nghiệp qua Data Warehouse. Ví dụ, kho dữ liệu sẽ chỉ ra một số điểm nóng chưa được tối ưu qua số liệu số liệu so sánh trực quan. Từ đó ban lãnh đạo có căn cứ đưa ra các quyết định cải tiến kịp thời, định hướng đúng phân khúc khách hàng, liên tục nâng cao chất lượng sản phẩm, dịch vụ và tăng khả năng cạnh tranh trên thị trường.
6. Kết Luận

- VDI và ALPACA Việt Nam ký kết hợp tác chiến lược - Tháng mười một 13, 2025
- Thu đoàn viên – Hành trình chia sẻ yêu thương - Tháng 10 31, 2025
- VDI tham gia đặt booth và tham luận tại Ngày chuyển đổi số tỉnh Bắc Ninh 2025 - Tháng 10 16, 2025